
Como a gente classifica milhões de itens
Publicado em 26 de junho de 2026 - 7 min de leitura
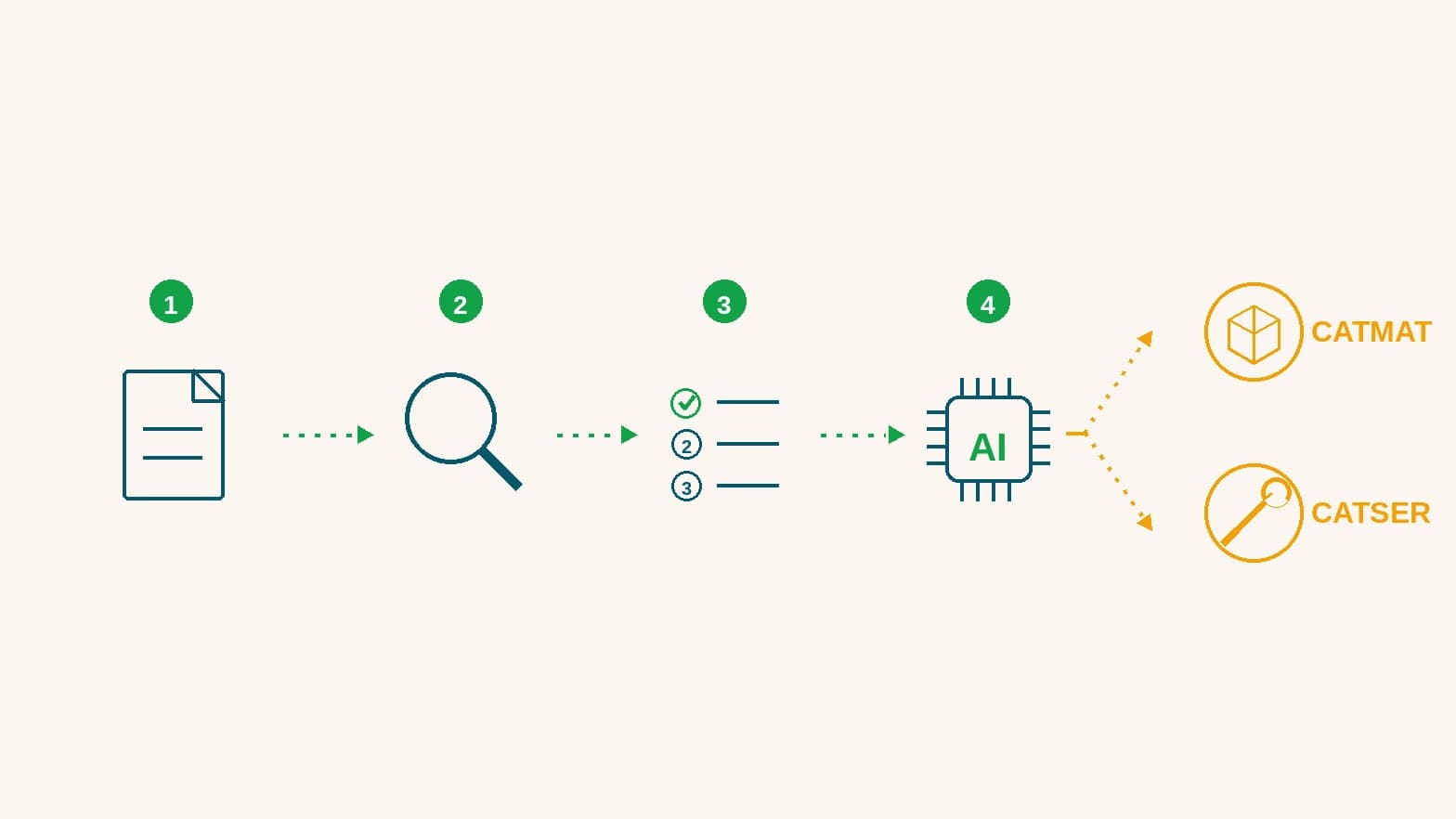
Toda licitação vem com uma lista de itens. Cada item precisa cair em um código oficial do governo.
O texto vem do jeito que cada órgão escreve:
- "caneta esferográfica azul corpo plástico"
- "PARAFUSO SEXTAVADO M8"
- "caneta esferog. azul cx c/50"
- "cadeira giratória, base em aço, revestida em tecido, com braço e regulagem"
Às vezes o item vem curto. Às vezes vem detalhado demais. Isso ajuda a entender a compra, mas vira custo quando cada linha precisa passar por um serviço de IA.
A gente começou pelo Compras.gov.br, antigo Comprasnet, por um motivo simples: o próprio governo apresenta ele como o maior site de compras públicas do Brasil. É ali que aparece muito CATMAT e CATSER. Se a classificação funciona bem nesse portal, ela vira uma boa base para comparar compras vindas de outros lugares.
Esse trabalho também prepara a Pesquisa de Preço da Licitei, que está em beta. Para comparar preço, a ferramenta precisa saber quando textos diferentes falam do mesmo item. A Pesquisa de Preço vai ganhar um post próprio. Aqui o foco é só classificar o item.
Hoje seguimos este caminho:
- Procuramos por palavras parecidas.
- Se ficar dúvida, fazemos um desempate entre as melhores opções.
- Só os casos difíceis vão para o Cat-rank-1-flash-lite.
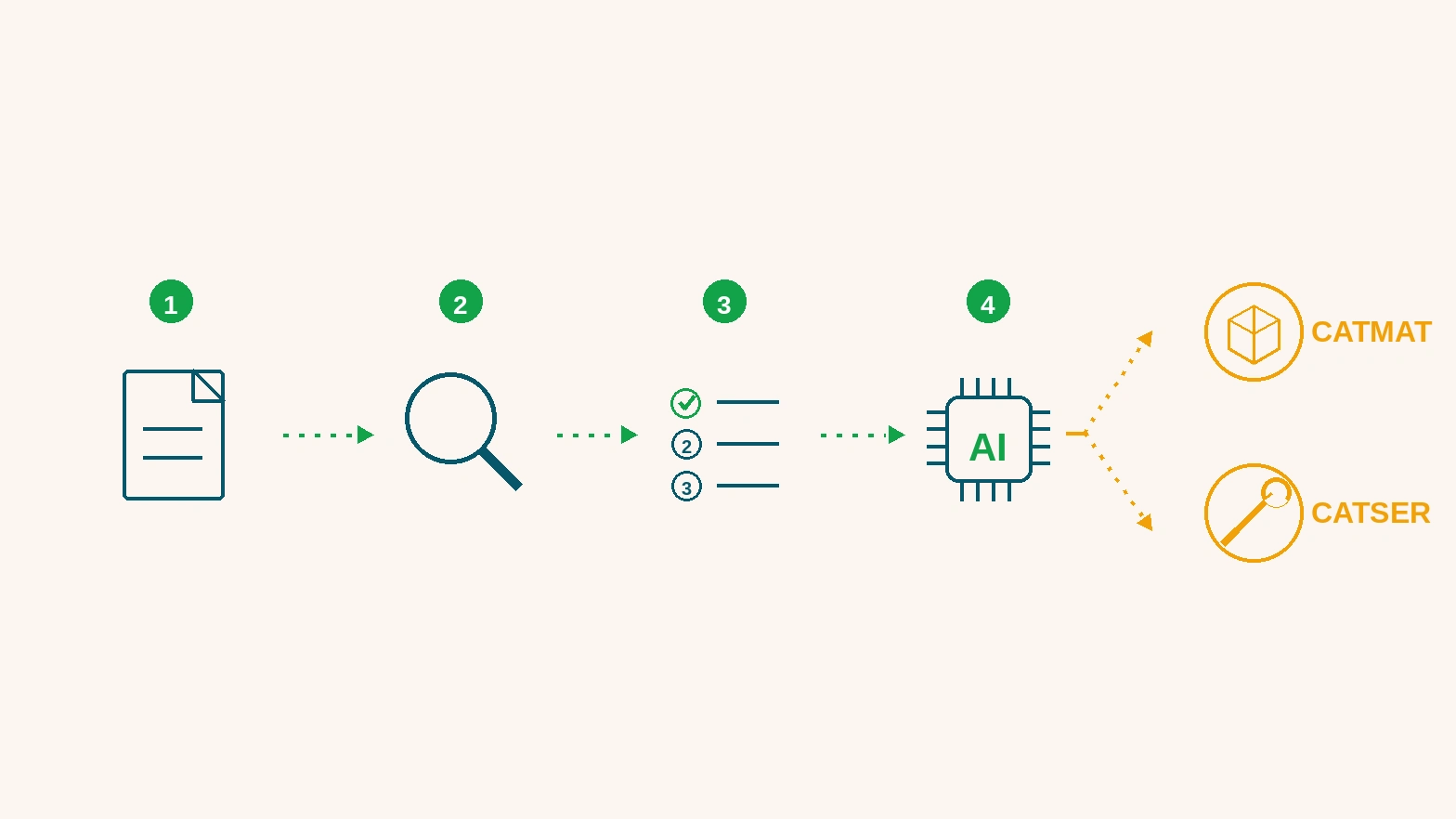
CATMAT e CATSER
CATMAT é a lista oficial de materiais. CATSER é a lista oficial de serviços.
Exemplos:
- caneta, papel e cadeira entram em CATMAT;
- limpeza, manutenção e instalação entram em CATSER.
O código ajuda a juntar compras parecidas. Dois órgãos podem escrever textos diferentes, mas comprar a mesma coisa. O código faz essa ponte.
| Catálogo | Como o código se organiza |
|---|---|
| CATMAT | grupo → classe → tipo do material → item |
| CATSER | grupo → classe → serviço |
Na base pública que usamos, existem 342.599 itens CATMAT, 20.319 tipos de material e 3.089 serviços CATSER.
O Brasil também tem listas locais. Minas Gerais, por exemplo, usa CATMAS. A gente transforma essas listas para CATMAT/CATSER antes de comparar preço, procura e histórico.
1. Busca por palavras
A primeira parte parece uma busca normal.
O item:
parafuso sextavado M8
vira uma consulta. A busca procura textos com palavras, medidas e nomes parecidos.
Usamos BM25. O nome é técnico, mas a ideia é simples:
- palavra rara ajuda mais;
- repetir a mesma palavra ajuda só até certo ponto;
- texto grande não ganha só por ser grande.
Em forma curta:
Antes da busca, limpamos o texto sem apagar o que decide a compra. "M8", "1 L", "9,5 mm" e "70%" ficam. Muitas vezes a medida separa dois itens parecidos.
Se o primeiro resultado fica muito melhor que o segundo, aceitamos ali mesmo.
| Item | Melhor opção | Segunda opção | Decisão |
|---|---|---|---|
| caneta azul | caneta esferográfica | caneta marca-texto | aceita a primeira |
| parafuso M8 | parafuso sextavado | parafuso francês | manda para desempate |
2. Desempate entre opções parecidas
Alguns itens continuam difíceis depois da busca.
álcool 70%
Pode ser álcool líquido, álcool em gel, produto de limpeza, insumo hospitalar ou outro item parecido. A palavra "álcool" sozinha não resolve.
Nessa parte, o sistema não olha o catálogo inteiro. Ele recebe as 40 melhores opções da busca e escolhe entre elas. Fica menor: 40 opções, não mais de 23 mil grupos.
O treino usa casos reais. A gente pega itens que a busca encontraria no dia a dia, com erro, abreviação e texto estranho. Isso ensina o desempate a lidar com o que chega de verdade.
Quando o desempate fica seguro, aceitamos. Quando ainda fica apertado, chamamos o Cat-rank-1-flash-lite.
3. Cat-rank-1-flash-lite
Cat-rank-1-flash-lite é o nosso modelo para essa tarefa. Ele vem de um Qwen3-4B treinado com exemplos de CATMAT e CATSER.
Ele recebe o texto do item e 40 opções. Não conversa. Não explica. Não inventa uma resposta livre. Ele só escolhe o código.
A resposta esperada é curta:
Isso importa porque resposta curta é mais fácil de conferir. Se o modelo tentar escrever explicação ou fugir do padrão, a gente rejeita.
O teste com 1.000 itens
O teste mede só a última parte. A pergunta é:
Dado o texto do item e 40 opções vindas da busca, qual é o código certo?
Usamos 1.000 itens reais: 500 materiais CATMAT e 500 serviços CATSER. Em todos os casos, o código certo está entre as 40 opções.
Cada modelo recebe o mesmo item e a mesma lista. Publicamos o teste no GitHub: Licitei/catmat-catser-benchmark.
| Modelo | Acerto | Preço por 1.000 itens difíceis |
|---|---|---|
| Claude Haiku 4.5 | 86,9% | US$ 1,292 |
| Cat-rank-1-flash-lite | 84,1% | US$ 0,027 |
| Gemini 3.1 Flash-Lite | 83,6% | US$ 0,327 |
| GPT-5.4 mini | 79,5% | US$ 0,981 |
GPT-5.4 mini e Claude Haiku 4.5 foram testados em menor volume. Eles entram como sinal, não como prova final.
![]()
Claude ficou acima no teste. O Cat-rank ficou perto, custando bem menos por item difícil. Esse é o ponto: chegar perto em qualidade, com custo baixo e resposta fácil de validar.
Custo na nossa média
A conta usa a média que vemos hoje:
Antes de fechar esse número, conferimos o CSV mensal mais recente do Portal de Dados Abertos do Compras.gov.br: 209.464 itens em 20.044 compras. A média dá 10,45 itens por compra. Para não inflar a conta, arredondamos para 10 itens por licitação.
- 5 mil licitações por hora;
- 10 itens por licitação;
- 24 horas por dia;
- 22 dias úteis por mês.
Isso dá 26,4 milhões de itens por mês, já sem contar finais de semana.
Se cada item fosse direto para um serviço de IA, pagaríamos por todos os 26,4 milhões. No nosso caminho, a busca e o desempate resolvem a maior parte antes. Se só 10% chegam ao Cat-rank, o modelo vê 2,6 milhões de itens por mês.
| Caminho | Itens que chegam ao modelo | Custo mensal estimado |
|---|---|---|
| Tudo no Claude Haiku 4.5 | 26,4 milhões/mês | ~US$ 34.000 |
| Tudo no GPT-5.4 mini | 26,4 milhões/mês | ~US$ 26.000 |
| Tudo no Gemini 3.1 Flash-Lite | 26,4 milhões/mês | ~US$ 9.000 |
| Tudo no Cat-rank-1-flash-lite | 26,4 milhões/mês | ~US$ 700 |
| Caminho real | 2,6 milhões/mês | ~US$ 70 |
![]()
Para ver o tamanho do problema por outro ângulo, este seria o custo de rodar só com modelos, sem busca antes:
![]()
A economia maior não vem de usar um modelo menor. Vem de não chamar modelo quando a busca já resolveu.
Por que não mandar tudo para um serviço pronto
Um serviço pronto precisa receber muita explicação em cada item:
- o que é CATMAT;
- o que é CATSER;
- quais opções ele pode escolher;
- como deve responder.
Essa explicação vira texto cobrado. Quanto maior a descrição do item, maior a conta.
No Cat-rank, parte dessa explicação já está dentro do treino. A pergunta fica menor e a resposta também. Para pouco volume, um serviço pronto pode fazer sentido. Para volume alto todo dia, treinar e rodar o próprio modelo começa a compensar.
Onde a gente controla custo e erro
A gente controla o quanto passa de uma parte para a outra.
Se a busca precisa ter muita certeza, mais itens vão para o desempate. Se o desempate também precisa ter muita certeza, mais itens vão para o Cat-rank.
Mais cuidado custa mais dinheiro. Menos cuidado custa menos, mas aumenta o risco de erro.
Também ajustamos CATMAT e CATSER separados, porque material e serviço se confundem de jeitos diferentes.
No fim, a ideia é simples: resolver barato tudo que é fácil e guardar o modelo para o que realmente precisa dele.
Referências
Catálogos e portais:
- Compras.gov.br, Portal de Compras do Governo Federal
- Catálogo CATMAT/CATSER, Governo Federal
- Catálogo Eletrônico de Padronização, PNCP
- CATMAS Minas Gerais, Compras MG
Preços públicos usados nas estimativas:
Teste próprio:
Gostou? Compartilhe
Conteúdos relacionados
Score do Órgão agora é oficial: um número de 0 a 100 para o risco antes de licitar
23/06/26

Due diligence de fornecedores em licitações com dados públicos e IA
11/06/26
Score do Órgão e da Cidade: avalie o risco de calote antes de licitar
02/06/26